

The Soundex Algorithm in Python


Soundex is one of a number of phonetic algorithms which assign values to words or names so that they can be compared for similarity of pronounciation. It is probably the best know such algorithm as it is built in to most major RDBMSs, as well as PHP and other languages. For this post I will write an implementation in Python.
It doesn't take much thought to realise that the whole area of phonetic algorithms is a minefield, and Soundex itself is rather restricted in its usefulness. In fact, after writing this implementation I came to the conclusion that it is fairly mediocre but at least coding it up does give a better understanding of how it works and therefore its usefulness and limitations.
The Algorithm
The purpose of the algorithm is to create for a given word a four-character string. The first character is the first character of the input string. The subsequent three characters are any of the numbers 1 to 6, padded to the right with zeros if necessary. The idea is that words that sound the same but are spelled differently will have the same Soundex encoding.
The steps involved are:
Copy the first character of the input string to the first character of the output string
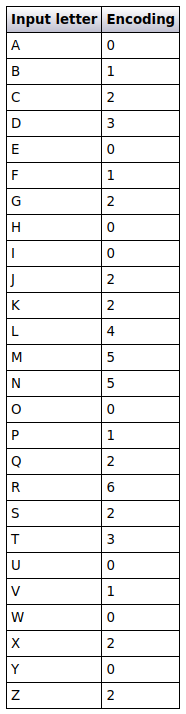
For subsequent characters in the input string, add digits to the output string according to the table below, up to a maximum of three digits (ie. a total output string length of 4). Note that a number of input letters are ignored, including all vowels. Also, further occurences of an input letter with the same encoding are ignored.
If we reach the end of the input string before the output string reaches 4 characters, pad it to the right with zeros.
Letter Encodings
This table lists the digits assigned to the letters A-Z. I have assigned 0 to letters which are ignored, and note that uppercase and lowercase letters are treated the same.
The Code
This project consists of two Python files, soundex.py which implements the algorithm, and soundexdemo.py to try it out. You can clone/download the files from Github.
This is soundex.py.
def soundex(name: str) -> str:
"""
The Soundex algorithm assigns a 1-letter + 3-digit code to strings,
the intention being that strings pronounced the same but spelled
differently have identical encodings; words pronounced similarly
should have similar encodings.
"""
soundexcoding = [' ', ' ', ' ', ' ']
soundexcodingindex = 1
# ABCDEFGHIJKLMNOPQRSTUVWXYZ
mappings = "01230120022455012623010202"
soundexcoding[0] = name[0].upper()
for i in range(1, len(name)):
c = ord(name[i].upper()) - 65
if c >= 0 and c <= 25:
if mappings[c] != '0':
if mappings[c] != soundexcoding[soundexcodingindex-1]:
soundexcoding[soundexcodingindex] = mappings[c]
soundexcodingindex += 1
if soundexcodingindex > 3:
break
if soundexcodingindex <= 3:
while(soundexcodingindex <= 3):
soundexcoding[soundexcodingindex] = '0'
soundexcodingindex += 1
return ''.join(soundexcoding) The function argument is the name to be encoded, and we then create a list of four spaces for the encoding which will be replaced by the actual encoding. The soundexcodingindex variable is initialised to 1 as this is where we will start adding numbers. Next a mappings string is created to represent the table above, and then the first character of the encoding is set to the first character of the input string.
Next we enter a for loop through the input string; note that the loop starts at 1 as we have already dealt with the first character. Within the loop we assign c to the current input letter's ASCII code using the ord function, converted to upper case. We then subtract 65 so the numeric value corresponds to the indexes of the mappings list.
The next step is to check the value is within the range 0 to 25, ie. an uppercase letter. If not it is ignored, but if so we check if its corresponding numeric value is not 0. We then check the value is not the same as the previous to implement the rule that consecutive identical values are skipped, and then set the next value of the output string to the correct number. The soundexcodingindex variable is then incremented before we check if it is more than 3; if so we break out of the loop.
Finally, we need to check if we have not yet filled up the encoding list, which can happen if there are not enough encodable letters in the input string. If this is the case we simply fill in the empty values with 0s in a while loop.
The return value is the encoding list converted to a string with join.
That's the algorithm implemented so let's look at main.py.
import soundex
def main():
"""
Demonstration of the Soundex module, creating lists of name pairs
and running them through the soundex method before printing results.
"""
print("-----------------")
print("| codedrome.com |")
print("| Soundex |")
print("-----------------\n")
names1 = ["Johnson", "Adams", "Davis", "Simons", "Richards", "Taylor", "Carter", "Stevenson", "Taylor", "Smith", "McDonald", "Harris", "Sim", "Williams", "Baker", "Wells", "Fraser", "Jones", "Wilks", "Hunt", "Sanders", "Parsons", "Robson", "Harker"]
names2 = ["Jonson", "Addams", "Davies", "Simmons", "Richardson", "Tailor", "Chater", "Stephenson", "Naylor", "Smythe", "MacDonald", "Harrys", "Sym", "Wilson", "Barker", "Wills", "Frazer", "Johns", "Wilkinson", "Hunter", "Saunders", "Pearson", "Robertson", "Parker"]
for i in range(0, len(names1)):
s1 = soundex.soundex(names1[i])
s2 = soundex.soundex(names2[i])
print(f"{names1[i]:20s}{s1:4s} {names2[i]:20s}{s2:4s}")
if __name__ == "__main__":
main() The main function first creates a couple of string lists, each pair of names being similar to some degree. We then loop through the name pairs, calling the soundex function for each, and finally print out the names and their Soundex encodings.
Now run the program with this command in your terminal…
python3 main.py
…which will give you this output.
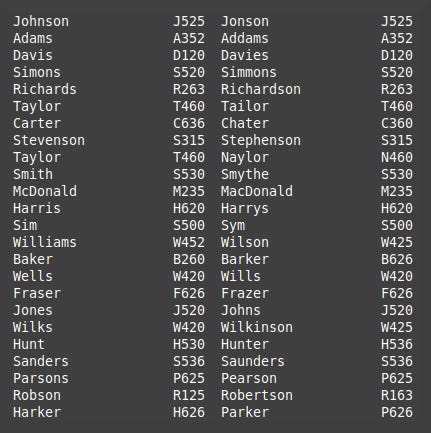
As you can see the algorithm is not perfect. Even with this small selection of names a few problems are apparent. Ignoring repeating values means Simons and Simmons are given the same encoding, and using only the first few letters means Richards and Richardson are also encoded the same. Ignoring vowels means that Wells and Wills, Sanders and Saunders, Parsons and Pearson are all given the same encodings despite not actually being homophones.