

Testing the Performance of Python Named Tuples
Are named tuples slower than ordinary ones? Let's find out. (Spoiler alert: yes, a bit.)


Python Tuples and Named Tuples
This section is a brief overview of tuples and named tuples in Python. If you already understand this topic you might want to skip straight to the next section.
A tuple is an immutable data structure which means that it is created with a collection of values but thereafter is read-only: you can access the values but cannot add, remove or edit them. The following code snippet illustrates creating a tuple to hold a coordinate pair and then printing the two values.
point = (65, 28)
print(point[0])
print(point[1])I'm sure many people write code just like this every day with no problems but it's not ideal in terms of either readability or maintainability. In the print statements there's nothing to indicate that [0] and [1] represent x and y coordinates respectively. Worse still, say you or someone else decides the point needs a name or description:
point = ("Start point", 65, 28)
print(point[0])
print(point[1])Now point[0] is no longer the x-coordinate and point[1] is no longer the y-coordinate. We have a bug! It's easy to spot here but in The Real World these bits of code could be a long way apart, and the values could be used a number of times in various different places.
Problems like this can be avoided using named tuples which, as the name implies, allow values to be accessed by name rather than indexes. This code snippet replicates that above but using named tuples.
Point = namedtuple("Point", "x, y")
point_b = Point(122, 68)
print(point_b.x)
print(point_b.y)The first line declares a new namedtuple type (note the convention of using an uppercase first letter as you would with a class) with the specified name and items, and the second line creates a variable of the new type. The print statements show that you no longer need to remember how to index the tuple when writing code, and the meaning of each item is obvious from its name.
The problems caused by changing tuple declarations are also solved by using named tuples.
Point = namedtuple("Point", "name, x, y")
point_b = Point("End point", 122, 68)
print(point_b.x)
print(point_b.y)Here I have added a name but the problem of indexes being shifted has now gone away.
I use named tuples frequently for the reasons outlined above but for a while have been wondering whether there is a performance hit. To be precise I was sure there must be a performance hit due to the necessity of converting names such as x and y to memory location offsets, but just how severe is it? Finding out is pretty simple as we'll see.
The Project
For this project I'll write a few simple bits of code to establish how much using named tuples slows things down compared to ordinary indexed tuples. The code creates a large number of both ordinary and named tuples, timing how long each type takes, and then outputs the percentage difference.
The project consists of a single file called namedtupleperformancetest.py which you can clone/download from the Github repository.
The Code
This is the entire code listing.
namedtupleperformancetest.py
from collections import namedtuple
import random
import time
def main():
"""
Experiment to determine whether named tuples cause
a performance slowdown compared to ordinary tuples.
SPOILER ALERT
They do, by around 10%.
This code creates a large number of named tuples
and ordinary tuples containing x and y coordinates,
calculates the times taken for each,
and then outputs the percentage difference.
"""
print("--------------------")
print("| codedrome.com |")
print("| Named Tuple |")
print("| Performance Test |")
print("--------------------\n")
iterations = 1_000_000
# declare a namedtuple for later use
Point = namedtuple("Point", "x, y")
random.seed(42)
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# pick up a time value just before starting the loop
start_nt = time.perf_counter()
for i in range(iterations):
# create a Point named tuple with random values
point = Point(random.randint(0, 24) , random.randint(0, 16))
# read the values into variables
# this is just to include access in the test
x = point.x
x = point.y
# pick up another time value just after the loop finishes
end_nt = time.perf_counter()
# calculate the ellapsed time
# (nb according to the official Python documentation
# https://docs.python.org/3/library/time.html
# this is the only meaningful use for values obtained
# using time.perf_counter(). It states:
# "The reference point of the returned value is undefined...")
duration_nt = end_nt - start_nt
print(f"time taken with namedtuple: {duration_nt}s")
#~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# This is a repeat of the previous code with ordinary tuples
start_t = time.perf_counter()
for i in range(iterations):
point = (random.randint(0, 24) , random.randint(0, 16))
x = point[0]
x = point[1]
end_t = time.perf_counter()
duration_t = end_t - start_t
print(f"time taken with tuple: {duration_t}s")
difference = round( (duration_t / duration_nt) * 100, 2)
print(f"tuple time as percentage of namedtuple time {difference}%")
if __name__ == "__main__":
main()At the top of the file we import namedtuple which lives in the collections module, as well as random for creating coordinate values, and time for measuring performance.
As the code is very simple I've kept it all in the main function which starts off by initializing an iterations variable to 1 million. This is a big enough number to provide a reasonable number of tests without taking a tedious amount of time. A Point namedtuple is declared with x- and y- coordinates, and random is seeded.
The following two sections of code do essentially the same thing but the first uses Point namedtuples and the second uses ordinary numberically-indexed tuples.
Firstly start_nt is initialised with a value from time.perf_counter(); this is a floating point number representing seconds and fractions of seconds intended to be used for timing purposes. Next comes a loop iterating to the count specified by iterations, creating and accessing the items of a tuple in each iteration.
Please note the comment about time.perf_counter(), and visit the link for more detailed information.
After the loop finishes we pick up another value from time.perf_counter(), and then calculate and print the time taken.
As I mentioned this process is carried out twice, once with namedtuples and once with regular tuples. Finally the two duration times are used to calculate the percentage difference, rounded to 2dp, which is then printed.
Running the Program
Run the code with this command...
python3 namedtupleperformancetest.py
...and after a few seconds you'll see something like this.
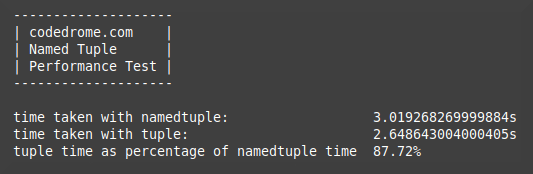
I ran the program a number of times and got results between around 82% and 92%. If you got significantly different results please let me know, but don't ask me to provide an explanation!
Conclusion
So we have discovered that there is a minor performance hit when using named tuples compared to ordinary tuples. I discussed the advantages of named tuples at the beginning of this article but whether or not they outweigh the slight slowdown is a moot point.
I would suggest a rule-of-thumb answer to that question: if you need one or a few tuples with a small number of writes and/or reads then go ahead and used named tuples. However, if you need a large/huge/gigantic number of tuples or a lot of reads/writes then go with ordinary tuples.
An even shorter rule-of-thumb answer is: just use your own judgement and common sense!